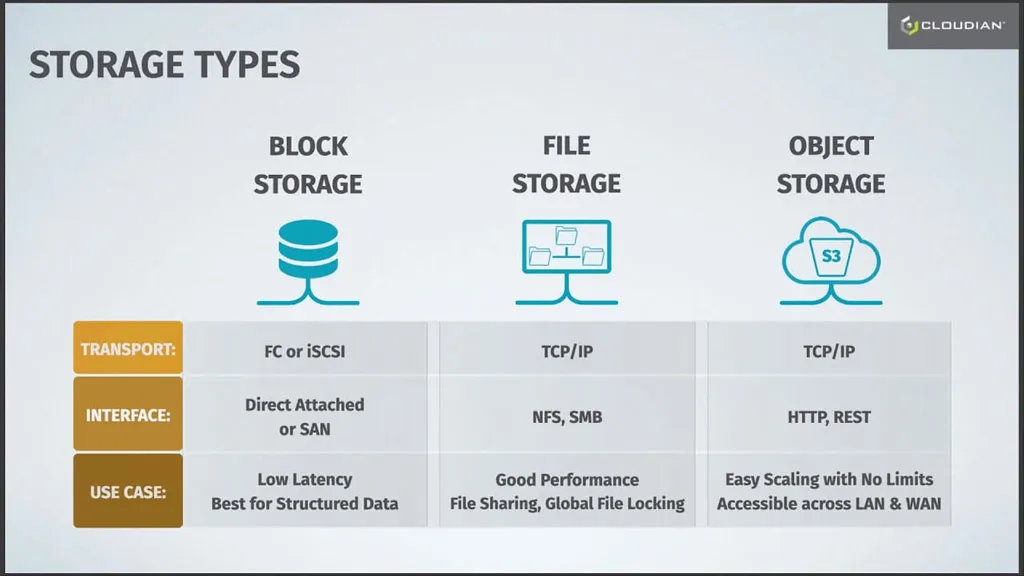
storage types
Object storage
In object storage systems, data blocks that make up a file or “object”, together with its metadata, are all kept together. Extra metadata is added to each object, which makes it possible to access data with no hierarchy. All objects are placed in a unified address space. In order to find an object, users provide a unique ID.
Object-based storage uses TCP/IP as its transport, and devices communicate using HTTP and REST APIs.
Metadata is an important part of object storage technology. Metadata is determined by the user, and allows flexible analysis and retrieval of the data in a storage pool, based on its function and characteristics.
The main advantage of object storage is that you can group devices into large storage pools, and distribute those pools across multiple locations. This not only allows unlimited scale, but also improves resilience and high availability of the data.
Programmability
Data in an object storage system should be accessible via an API, typically an HTTP-based RESTful API. Developers should be able to perform any action on storage pools, programmatically. Applications should be able query objects using their metadata, to find the required objects no matter where they are stored in a large storage pool.
Customizable Metadata
While file systems have metadata, the information is limited and basic (date/time created, date/time updated, owner, etc.). Object storage allows users to customize and add as many metadata tags as they need to easily locate the object later. For example, an X-ray could have information about the patient’s age and height, the type of injury, etc.
meta data
Object storage is known for its scalability and easy-to-use S3 APIs, but to make that object data useful for analytics, metadata about the objects sometimes needs to be added. This article describes a case study of adding and then using metadata of S3 objects with Cloudian’s HyperStore Analytics Platform (HAP). Starting with images stored in HyperStore object storage, we use a TensorFlow machine learning model to identify what’s depicted in the image, then attach those labels to each image as S3 metadata, and finally automatically index and search the object metadata using ElasticSearch and Kibana.
More Details: Enhancing Object Storage Analytics: Adding Metadata Labels to S3 Images with TensorFlow
Support for the S3 API
Back when object storage solutions were launched, the interfaces were proprietary. Few application developers wrote to these interfaces. Then Amazon created the Simple Storage Service, or “S3”. They also created a new interface, called the “S3 API”. The S3 API interface has since become a de-facto standard for object storage data transfer.
The existence of a de facto standard changed the game. Now, S3-compatible application developers have a stable and growing market for their applications. And service providers and S3-compatible storage vendors such as Cloudian have a growing user set deploying those applications. The combination sets the stage for rapid market growth.
Reference
What is Object Storage and Why Should You Care?
Enhancing Object Storage Analytics: Adding Metadata Labels to S3 Images with TensorFlow
0 Comments